Chapter 3 Using Generative AI
This page describes the results of our project using ChatGPT to scale up the CDC Clear Communication Index. We didn’t focus on whether ChatGPT performs well as a health literacy tool. Instead, we focused on the long-term impact of using it as one.
Our results show that you can’t predict how tools like ChatGPT will perform over time. So, you need to hire health literacy experts and community health workers to assess its outputs. Not just once, but for as long as you are using it.
3.1 Background
3.1.1 What is generative AI?
“Generative AI” is an approach to artificial intelligence. It focuses on making new content based on patterns in old content. A popular example is ChatGPT.
3.1.2 How can I use generative AI for health communication?
That depends on who you ask. A fan might say that your imagination is the only limit. Example: you can prompt it to provide health literacy feedback on your writing. It wasn’t designed for that task. But its massive training dataset might make it flexible enough to do so. A critic might say it’s not at all appropriate for public health. Example: it has environmental costs. It relies on stolen content. And it just makes things up.
3.1.3 How do I know whether AI-generated content is good enough?
You have to test it to find out. Define a specific task you want to use it on. Example: decide whether a Tweet includes a call to action. Prompt the AI system to do that task on lots of different Tweets. Then compare its outputs to your own decisions for each Tweet. Calculate a performance metric that describes how well the models’ outputs match your own decisions.
3.2 Research Findings
3.2.1 Will minor model updates affect performance?
It’s hard to say. We had 2 expert raters assess 260 US public health agency Tweets, using 6 items from the CDC Clear Communication. Example: does this material have a main message statement? Or: does this material include a behavioral recommendation?
A 3rd rater resolved any conflicts to create our gold-standard data. We then prompted the November 2023 version of ChatGPT 3.5 to apply the same items to the same Tweets. We did the same with the January 2024 version. We used MCC as our performance metric to describe how well each ChatGPT model aligned with our gold-standard data. For some tasks, both model versions were about the same. But for others there was a clear difference.
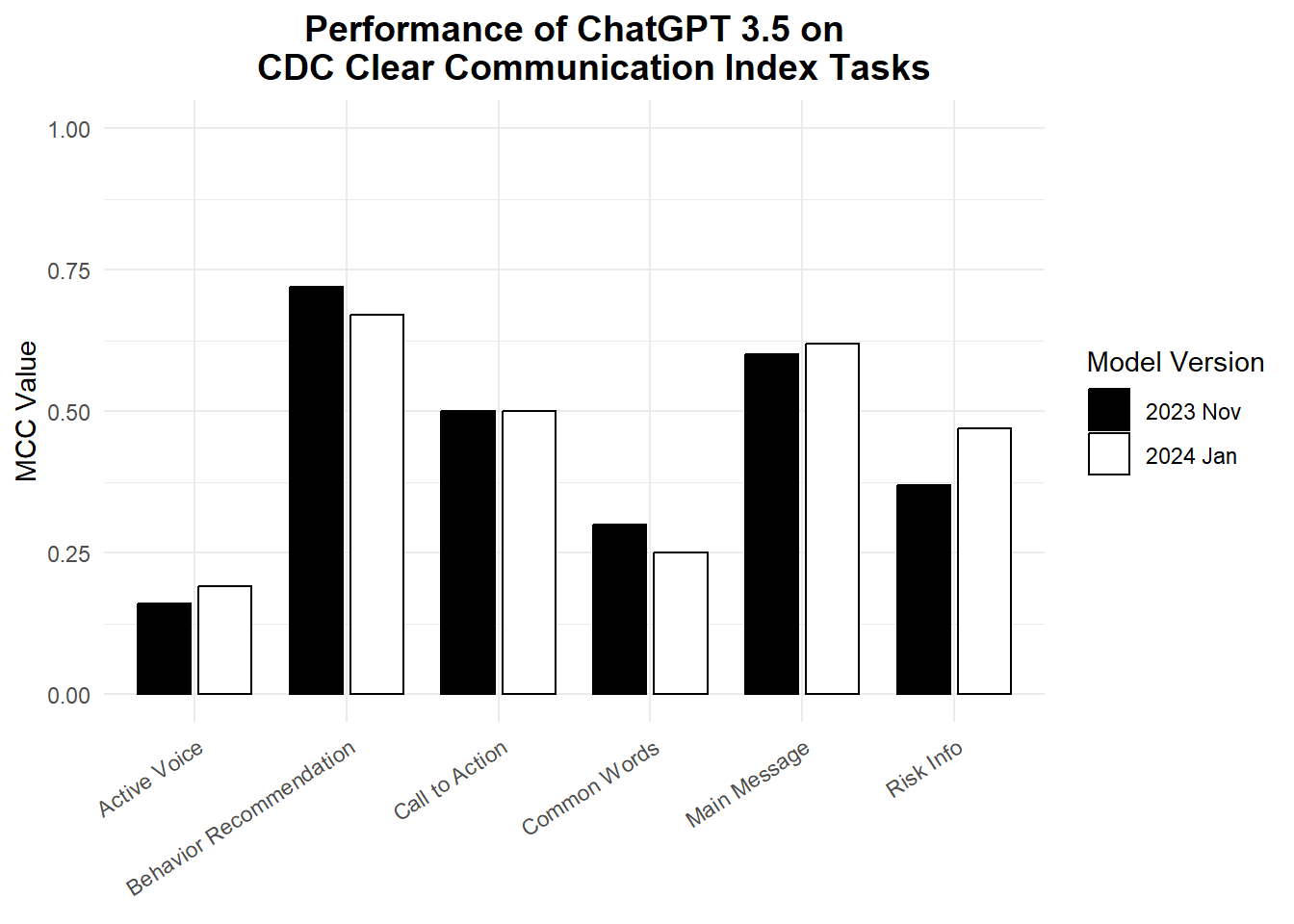
Figure 3.1: Our results show no clear pattern in performance. This means even so-called minor updates to an AI model need to be tested like brand new models.
3.2.2 Will more advanced models perform better?
Not necessarily. We prompted GPT 4-turbo and 4-o to apply the same items to the same Tweets as before. Again, we used MCC to describe how well each model aligned with our gold-standard data. The 4-o model is touted as the most advanced. But it did not always perform the best on these health communication tasks. Sometimes a GPT-3.5 model was the best. Sometimes the 4-turbo model was the best. There was no clear pattern.
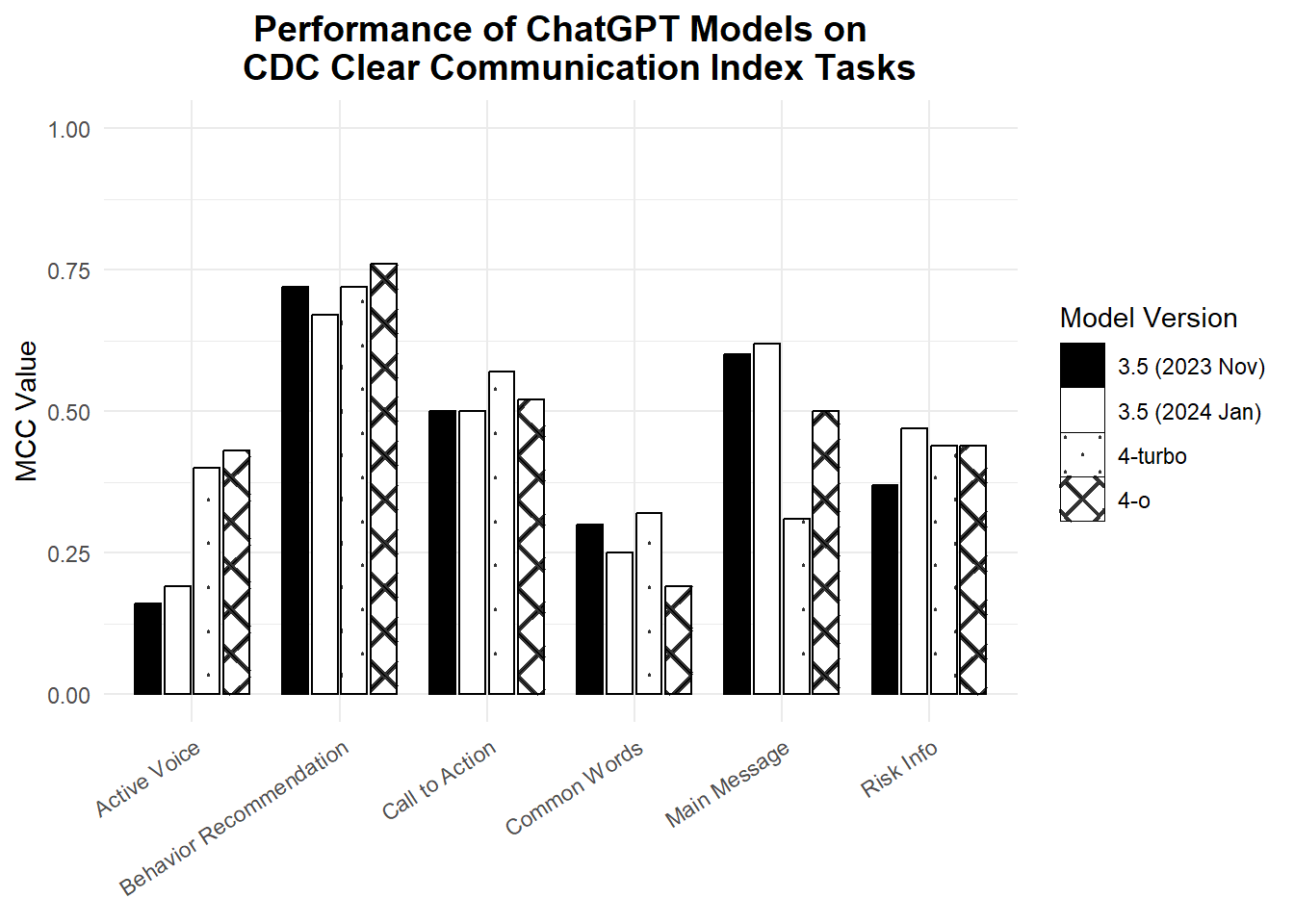
Figure 3.2: Our results show now clear pattern in performance. This means paing for a more advanced model can have mixed effects on health communication tasks.
3.3 Recommendations
3.3.1 For research
Our results cast doubt on how relevant tech industry benchmarks are for health communication. So, test large language models against a custom gold-standard validation dataset. Make your dataset so you can also draw insights from it without the use of AI.
3.3.2 For practice
Our results show that generative AI does not work the same across tasks we might think are similar. Example: after training someone, you might expect them to spot calls to action about as well as behavioral recommendations. But that wasn’t the case with ChatGPT. So, apply ChatGPT to specific tasks you know well. That way, you can judge its outputs over time without too much effort.
3.3.3 For policy
Our results highlight how generative AI can be unpredictable. So, health organizations should use generative AI only if they can commit to funding a transparent, long-term evaluation plan. This plan should cover the entire timeline of its expected use, across all use cases. Plain-language evaluation reports should be available to all communities served through these tools.